CMS Trigger Upgrade
To increase the sensitivity to searches for new physics and measurements of particle properties, the LHC ceased operation in early 2013 for a two-year shutdown to allow for maintenance and upgrades. This will enable the accelerator to operate with a 14 TeV centre of mass energy, the highest yet achieved, and significantly increase the reach of its experiments. As a consequence a large increase in the number of simultaneous particle collisions, known as pileup, is expected to exceed the capabilities of the current trigger system. It is of utmost importance therefore that the trigger system be upgraded to ensure that CMS retains sensitivity to physics searches such as signatures of supersymmetry and measurements of particle properties including that of the Higgs boson.
The MP7

The Imperial Master Processor, Virtex-7 (MP7) is a high-performance all-optical, data-stream processor designed to operate in the challenging conditions of the CMS trigger system at the Large Hadron Collider (LHC).
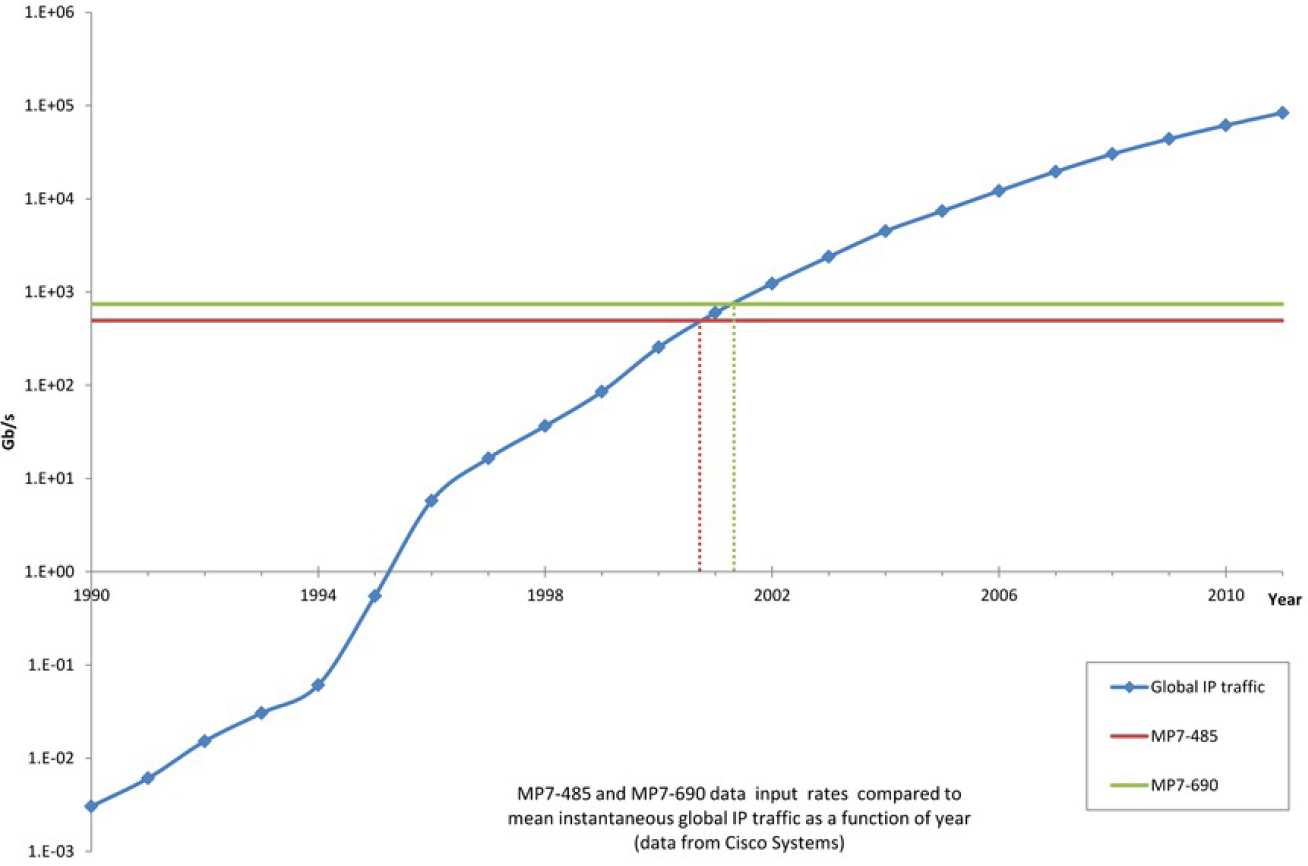
Utilising the high performance Xilinx Virtex-7 FPGA and state-of-the-art fibre optics technologies, the MP7 has the capability to input and output data at a rate of 3/4 Tbit per second, equivalent to the mean global traffic of the entire Internet in 2001. These features are crucial in the operation of the trigger at the LHC, where a latency budget of 3.2μs is afforded to readout and process the large volume trigger of data from the detector subsystems, equivalent to processing data at a rate of up to 10 Tbits per second.
The MP7 is the baseline trigger processor platform designed to operate in the challenging conditions that will be experienced in the upgraded LHC beam, performing the L1-triggering for the calorimetry systems. The capabilities of the MP7 will enable the performance of the upgraded system to far exceed that of the current trigger, improving the sensitivity and abilities of the CMS experiment. The power of the MP7 will allow the upgraded trigger system to far exceed the performance of the current trigger with far fewer processing boards. Currently the calorimeter trigger system processors fill a total of 13 telecoms racks, a system comprising entirely of MP7's would provide improved performance whilst only occupying 1/3 of a rack, greatly reducing network complexity and infrastructure requirements. The high-bandwidth and processing power of the MP7 will enable the upgraded trigger to exploit for the first time tower-level information of the calorimetry systems. The high performance FPGA will also allow for more sophisticated reconstruction algorithms to be employed and at a greater speed, greatly improving the performance of the trigger system and the CMS experiment as a whole.
More information on the MP7 processor can be found here.
Time-multiplexed triggering
In a conventional trigger (such as the current CMS calorimeter trigger) the experimental data are processed at increasingly coarse resolutions: at each processing stage the trigger performs clustering operations to build physics objects, which are then sorted in terms of importance. Depending on the number of parallel processing nodes, the result may need to be passed to a subsequent sorting stage to reduce the data rate into the next processing stage. If the CMS calorimeter trigger were to be upgraded using a conventional architecture, there would be two processing stages; a Regional Calorimeter Trigger which clusters and sorts electron/tau candidates at tower resolution and a Global Calorimeter Trigger which clusters jets at region or ½-region resolution.
In a time-multiplexed trigger, multiple data from a single bunch crossing (bx) are concatenated and delivered to a single processing system over multiple bx. This approach requires several processing systems operating in a “round-robin” fashion with processing system 1 takes bx = n, processing system 2 takes bx = n+1 and so on. This mode of operation is similar to the existing Higher Level Trigger (HLT), which uses ~1000 PC cores, each handling a single event, with one crucial difference: The timing and data flow are fully deterministic for a time-multiplexed trigger, whereas they are not in the Higher Level Trigger.
The advantage of a time-multiplexed trigger is that the boundaries between processing nodes that exist in a conventional trigger are removed and all the data is processed in one location, making the system very flexible.
Each processing node has all the input data from the bunch crossing it is processing, allowing algorithms to be performed which simply cannot be considered in a regional architecture. Furthermore, for algorithms that require large overlaps between neighbouring processing nodes in a conventional trigger architecture, a time-multiplexed system becomes much more efficient because the ratio of the area processed to the boundary area is substantially increased. This results in fewer cards and fewer interconnections, which also makes the subsequent sorting of trigger objects simpler, faster and, more importantly, more accurate since no partial sorting is required.